schema
Using the wizards in comand line mode
15/07/13 16:21 Filed in: Swingbench
I’ve just been reminded that not everybody knows that you can run swingbench in command line mode to use nearly all of it’s functionality. Whilst VNC means that you can use the graphical front end for most operations sometimes you need a little more flexibility. One area that this is particularly useful is when you’re creating large benchmark schemas for the SOE and SH benchmarks via the wizards (oewizard, shwizard). To find out what commands you can use just use the “-h” option. As you can see below there’s access to nearly all of the parameters (and a few more) that are available in the graphical user interface.
Using these parameters its possible to specify a complete install and drop operation from the command line. For example
This will create a 10 GB (Data) schema using 32 threads, use no partitioning and use the soe schema.
You can drop the same schema with the following command
I use this approach to create lots of schemas to automate some form of testing… The following enables me to create lots of schemas to analyse how the SOE benchmark performs as the size of the data set and index increase.
./oewizard -scale 5 -cs //oracle12c/orcl -dbap manager -ts SOE5 -tc 32 -nopart -u soe5 -p soe5 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe5.dbf
./oewizard -scale 10 -cs //oracle12c/orcl -dbap manager -ts SOE10 -tc 32 -nopart -u soe10 -p soe10 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe10.dbf
./oewizard -scale 20 -cs //oracle12c/orcl -dbap manager -ts SOE20 -tc 32 -nopart -u soe20 -p soe20 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe20.dbf
./oewizard -scale 40 -cs //oracle12c/orcl -dbap manager -ts SOE40 -tc 32 -nopart -u soe40 -p soe40 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe40.dbf
./oewizard -scale 80 -cs //oracle12c/orcl -dbap manager -ts SOE80 -tc 32 -nopart -u soe80 -p soe80 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe80.dbf
usage: parameters:
-allindexes build all indexes for schema
-bigfile use big file tablespaces
-cwizard config file
-cl run in character mode
-compositepart use a composite paritioning model if it exisits
-compress use default compression model if it exists
-create create benchmarks schema
-csconnectring for database
-dbadba username for schema creation
-dbappassword for schema creation
-debug turn on debugging output
-debugf turn on debugging output to file (debug.log)
-dfdatafile name used to create schema in
-drop drop benchmarks schema
-dtdriver type (oci|thin)
-g run in graphical mode (default)
-generate generate data for benchmark if available
-h,--help print this message
-hashpart use hash paritioning model if it exists
-hcccompress use HCC compression if it exisits
-nocompress don't use any database compression
-noindexes don't build any indexes for schema
-nopart don't use any database partitioning
-normalfile use normal file tablespaces
-oltpcompress use OLTP compression if it exisits
-ppassword for benchmark schema
-part use default paritioning model if it exists
-pkindexes only create primary keys for schema
-rangepart use a range paritioning model if it exisits
-s run in silent mode
-scalemulitiplier for default config
-spthe number of softparitions used. Defaults to cpu
count
-tcthe number of threads(parallelism) used to
generate data. Defaults to cpus*2
-tstablespace to create schema in
-uusername for benchmark schema
-v run in verbose mode when running from command
line
-versionversion of the benchmark to run
Using these parameters its possible to specify a complete install and drop operation from the command line. For example
./oewizard -scale 10 -cs //oracle12c/orcl -dbap manager -ts SOE -tc 32 -nopart -u soe -p soe -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe.dbf
This will create a 10 GB (Data) schema using 32 threads, use no partitioning and use the soe schema.
You can drop the same schema with the following command
./oewizard -scale 0.1 -cs //oracle12c/orcl -dbap manager -ts SOE -u soe -p soe -cl -drop
I use this approach to create lots of schemas to automate some form of testing… The following enables me to create lots of schemas to analyse how the SOE benchmark performs as the size of the data set and index increase.
./oewizard -scale 1 -cs //oracle12c/orcl -dbap manager -ts SOE1 -tc 32 -nopart -u soe1 -p soe1 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe1.dbf
./oewizard -scale 5 -cs //oracle12c/orcl -dbap manager -ts SOE5 -tc 32 -nopart -u soe5 -p soe5 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe5.dbf
./oewizard -scale 10 -cs //oracle12c/orcl -dbap manager -ts SOE10 -tc 32 -nopart -u soe10 -p soe10 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe10.dbf
./oewizard -scale 20 -cs //oracle12c/orcl -dbap manager -ts SOE20 -tc 32 -nopart -u soe20 -p soe20 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe20.dbf
./oewizard -scale 40 -cs //oracle12c/orcl -dbap manager -ts SOE40 -tc 32 -nopart -u soe40 -p soe40 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe40.dbf
./oewizard -scale 80 -cs //oracle12c/orcl -dbap manager -ts SOE80 -tc 32 -nopart -u soe80 -p soe80 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe80.dbf
Comments
New Build of Datagenerator
31/12/10 11:34 Filed in: Datagenerator
Im releasing a new build of Datagenerator simply because there hasn’t been one for a while. Thats not to say it hasn’t undergone significant changes. Most of them are as a result of enhancements to support schema creation for swingbench. In particular is the introduction of Pre and Post generation scripts. These allow me to run a complete schema creation from within datagenerator. These scripts appear as top level items from within the tree (see below).
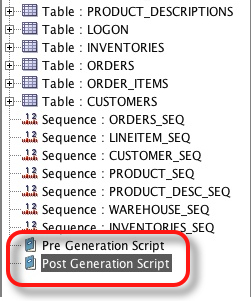
In the side panel you can now include scripts and parameters for the scripts.
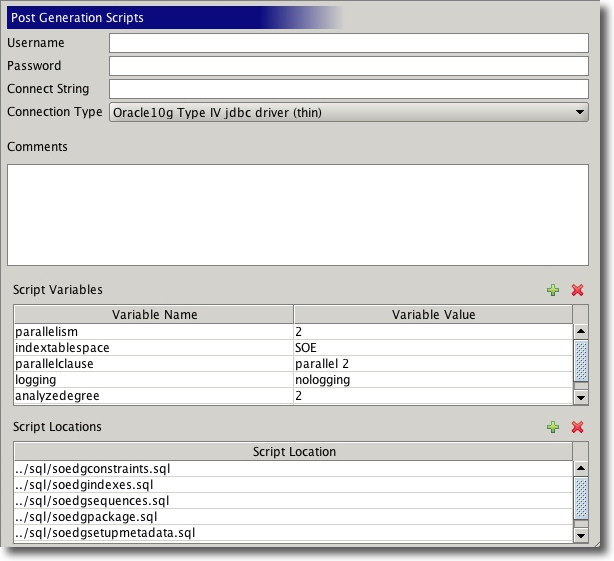
I’ve also included the script files used for generating the SH and SOE schemas used by swingbench. This should make it easier to understand what is going on and potentially create your own versions of the schemas.
In this release I’ve also improved the threading model and included one or two other performance enhancements....
In the next release I’m going to try and add support for for well know data items such as zip/post codes, NI numbers, Social Security etc.... as well as allowing users to plug their own data generators in.
You can download it from the usual place and as before leave comments below or via the comments page.
In the side panel you can now include scripts and parameters for the scripts.
I’ve also included the script files used for generating the SH and SOE schemas used by swingbench. This should make it easier to understand what is going on and potentially create your own versions of the schemas.
In this release I’ve also improved the threading model and included one or two other performance enhancements....
In the next release I’m going to try and add support for for well know data items such as zip/post codes, NI numbers, Social Security etc.... as well as allowing users to plug their own data generators in.
You can download it from the usual place and as before leave comments below or via the comments page.