Swingbench 2.8
I’m pleased to announce the release of Swingbench 2.8. It includes A new html front end to run and review benchmark runs New tool to render results with...

In my previous post “Going Big” I discussed the difference testing a data set of a representative size can make to the usefulness of a benchmark. Running a workload against a Swingbench data set that is entirely cached in-memory will only show the speed of memory and CPU, and will largely miss the impact I/O can have on the overall performance of your target platform. I’ve spoken to a number of Oracle customers that have struggled with the performance of their database having moved to the cloud and have neglected to evaluate the effect that disk I/O would have on the performance of their databases and as a result been forced to significantly re-size the shape of the VM needed. This resulted in significant increases in costs and soured the whole migration to the cloud and the benefits it can bring.
I also showed in my last post how to create a large data set for the Order Entry benchmark. It took 7 hours to create a scale 1000 schema with 1TB of data and 800GB of indexes. This could of course have been made much larger still. But in this case, it is sufficient to show the impact that the size of dataset can have when evaluating a target platform.
To evaluate the impact that larger datasets/databases can have on the performance of a database we will be creating 4 Order Entry schemas of 4 sizes.
| Schema scale | Data Size | Index Size | Rows in Line Items Table |
|---|---|---|---|
| 1 | 1.1GB | 900MB | 7,152,926 |
| 10 | 10GB | 9GB | 71,243,711 |
| 100 | 100GB | 82GB | 716,709,850 |
| 1000 | 1TB | 828GB | 7,167,190,000 |
A script similar to the following can be used to build the 4 schemas needed
./oewizard -v -cs domsatp -u soe1 -p YourPassw0rd -scale 1 -tc 128 -cl -dba admin -dbap YourPassw0rd^ -sp 96 -create -ro -bs 2048
./oewizard -v -cs domsatp -u soe10 -p YourPassw0rd -scale 10 -tc 128 -cl -dba admin -dbap YourPassw0rd^ -sp 96 -create -ro -bs 2048
./oewizard -v -cs domsatp -u soe100 -p YourPassw0rd -scale 10 -tc 128 -cl -dba admin -dbap YourPassw0rd^ -noindexes -sp 96 -create -ro -bs 2048
./sbutil -soe -cs domsatphigh -u soe100 -p YourPassw0rd -dup 10 -parallel 64
./sbutil -soe -cs domsatp -u soe100 -p YourPassw0rd -code
./oewizard -v -cs domsatp -u soe1000 -p YourPassw0rd -scale 10 -tc 128 -cl -dba admin -dbap YourPassw0rd^ -noindexes -sp 96 -create -ro -bs 2048
./sbutil -soe -cs domsatphigh -u soe1000 -p YourPassw0rd -dup 100 -parallel 64
./sbutil -soe -cs domsatp -u soe1000 -p YourPassw0rd -code
Look at the previous blog for an explanation on what these various commands do.
Save this content to a file such as buildschemas.sh in the Swingbench bin directory, and then run it with a command similar to
chmod +x buildschemas.sh
nohup ./buildschemas.sh &
This build will take 9-10 hours to complete on a reasonably powered server with fast storage i.e an 8 OCPU ADB Serverless instance.
After the datasets have been created we can now run a workload against these schemas in turn. Again I recommend creating a script with the following commands within
#! /bin/bash
echo $PATH
outputdir=$HOME/sizeresults
mkdir -p $outputdir
thread_count="64"
cpu_count="8"
./swingbench/bin/charbench -cs domsatp -u soe1 -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale1_uc${thread_count}_cpu${cpu_count}.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe10 -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale10_uc${thread_count}_cpu${cpu_count}.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe100 -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale100_uc${thread_count}_cpu${cpu_count}.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale1000_uc${thread_count}_cpu${cpu_count}.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe1 -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale1_uc${thread_count}_cpu${cpu_count}_2.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe10 -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale10_uc${thread_count}_cpu${cpu_count}_2.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe100 -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale100_uc${thread_count}_cpu${cpu_count}_2.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale1000_uc${thread_count}_cpu${cpu_count}_2.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe1 -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale1_uc${thread_count}_cpu${cpu_count}_3.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe10 -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale10_uc${thread_count}_cpu${cpu_count}_3.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe100 -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale100_uc${thread_count}_cpu${cpu_count}_3.xml -dbau admin -dbap YourPassword^ -s
./swingbench/bin/charbench -cs domsatp -u soe -p YourPassword -uc ${thread_count} -rt 0:05 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0 -r $outputdir/results_scale1000_uc${thread_count}_cpu${cpu_count}_3.xml -dbau admin -dbap YourPassword^ -s
This script should take about an hour to run and store the results in a directory called sizeresults in the home directory of the server you are running the workload from. You should end up with a directory containing 12 xml files looking like this.
$ ls sizeresults
results_scale1000_uc64_cpu8_2.xml results_scale100_uc64_cpu8_2.xml results_scale10_uc64_cpu8_2.xml results_scale1_uc64_cpu8_2.xml
results_scale1000_uc64_cpu8_3.xml results_scale100_uc64_cpu8_3.xml results_scale10_uc64_cpu8_3.xml results_scale1_uc64_cpu8_3.xml
results_scale1000_uc64_cpu8.xml results_scale100_uc64_cpu8.xml results_scale10_uc64_cpu8.xml results_scale1_uc64_cpu8.xml
The challenge is to parse these results into a meaningful document. You could use results2pdf to convert them into individual pdfs. and then copy the results that you are interested in. You could also use the Python script parse_results.py in the utility directory to create a table or CSV output (described here). Alternatively, you could parse them yourself. I developed a Jupyter workbook that I use to compare result files across a number of dimensions. It’s not “hands-off” and does require some understanding of Python.
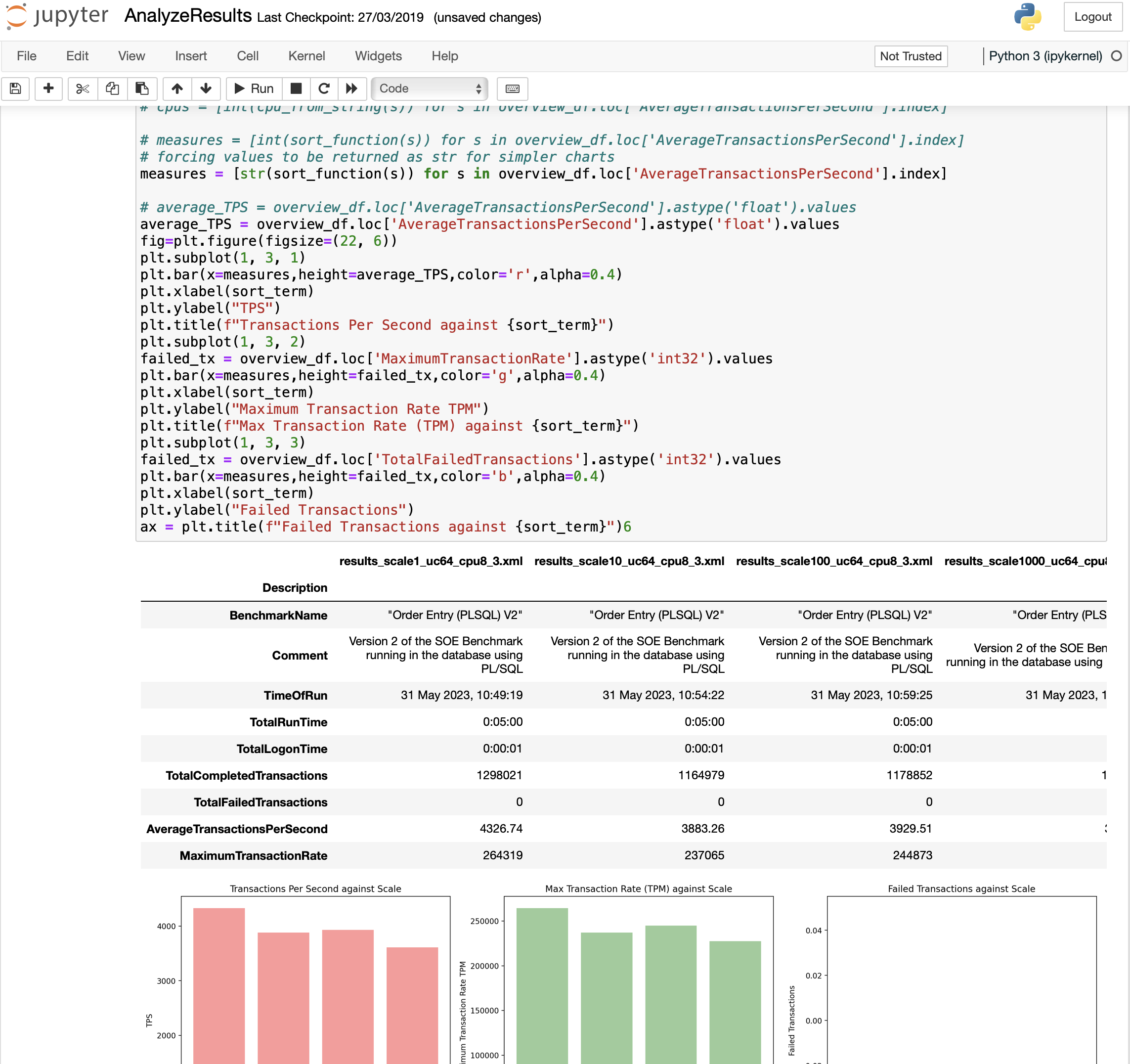
You can find a link to the Github repository here. I won’t spend the time explaining how this notebook works I’ve simply included a link to the repository for those that feel comfortable working with Python and Matplot Lib. For most users, I suggest using parse_results.py which I’ll include a more detailed blog at a later date
Having parsed the results, and compared the transactions per second it’s clear that there is an expected degradation in performance as the size of the database increases.
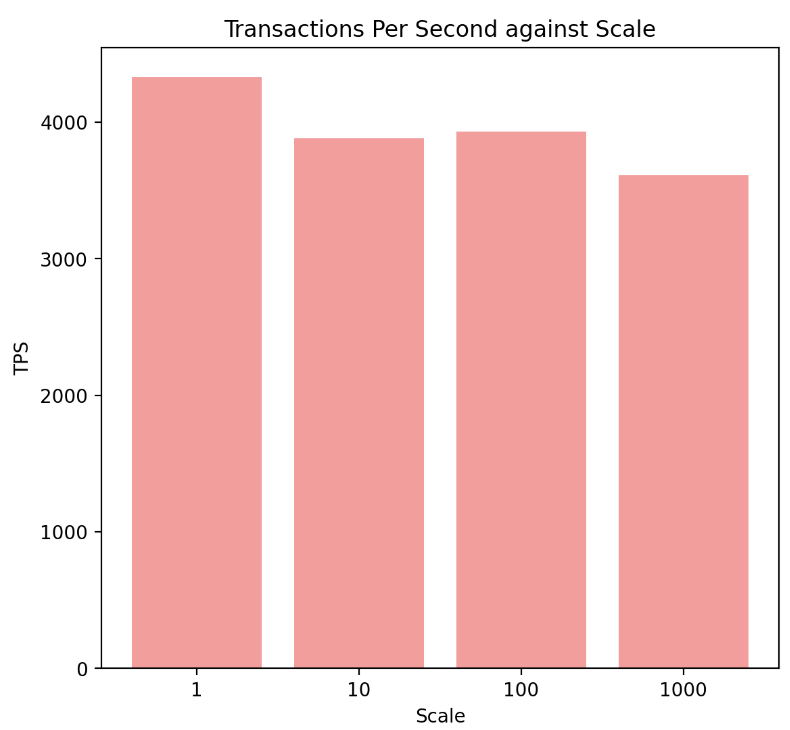
However, it’s not as dramatic as I think most people would imagine. Some of that’s down to the fact that all of the data access is driven by indexes but the indexes are still significantly bigger than the buffer-cache for the database instance. The reason the impact is less significant is primarily down to ADB and its very fast I/O particularly the flash cache in the storage cells. The difference in performance is still measurable though, about 16%, and would be significantly higher on other cloud platforms.
The impact on the size of the database can be seen when looking at the wait events during the runs…
A workload against a dataset of scale one shows the wait events been nearly entirely focused on the CPU and CPU scheduling
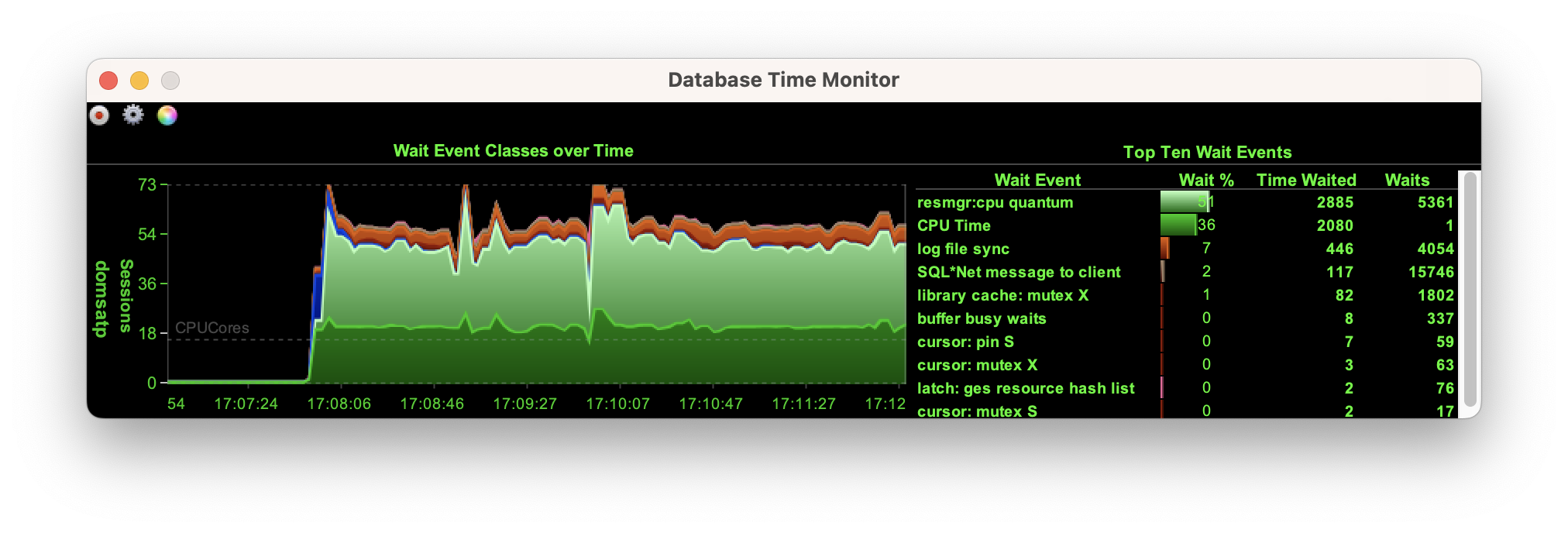
A workload against a dataset of scale ten still shows the wait events are focused on the CPU and CPU scheduling
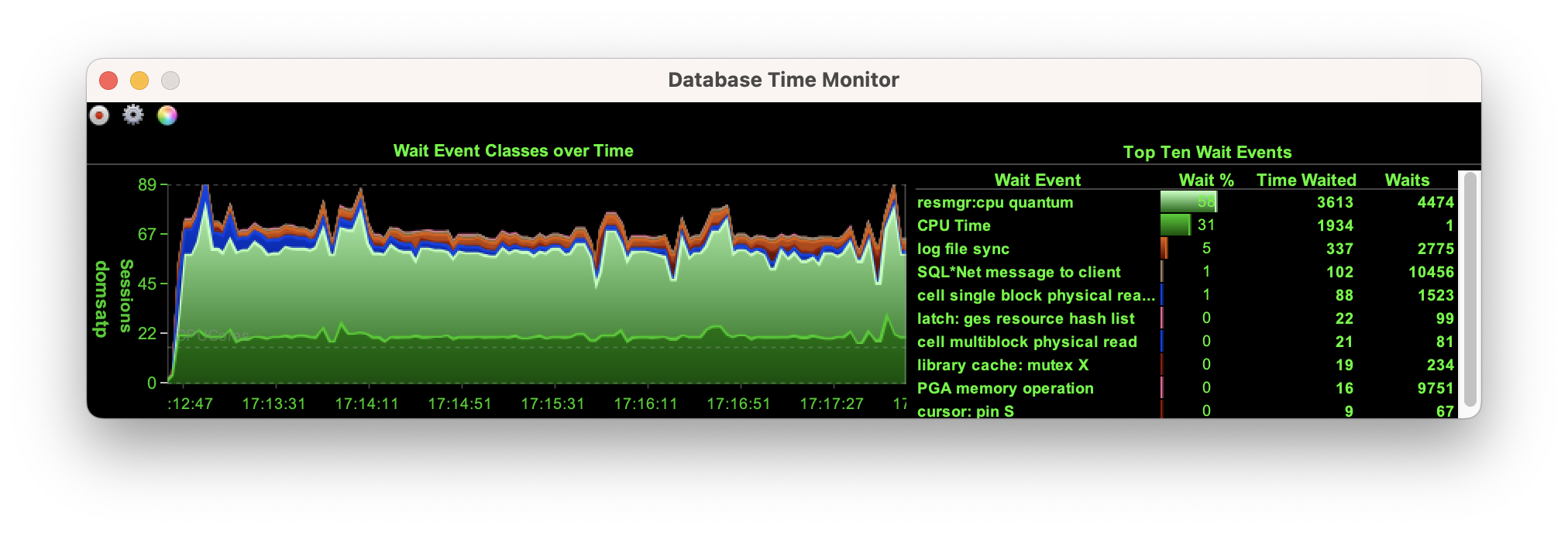
When we run the workload at a scale of a hundred we start to see the impact that the larger data set makes with significantly more I/O although this begins to settle down as the database caches the indexes.
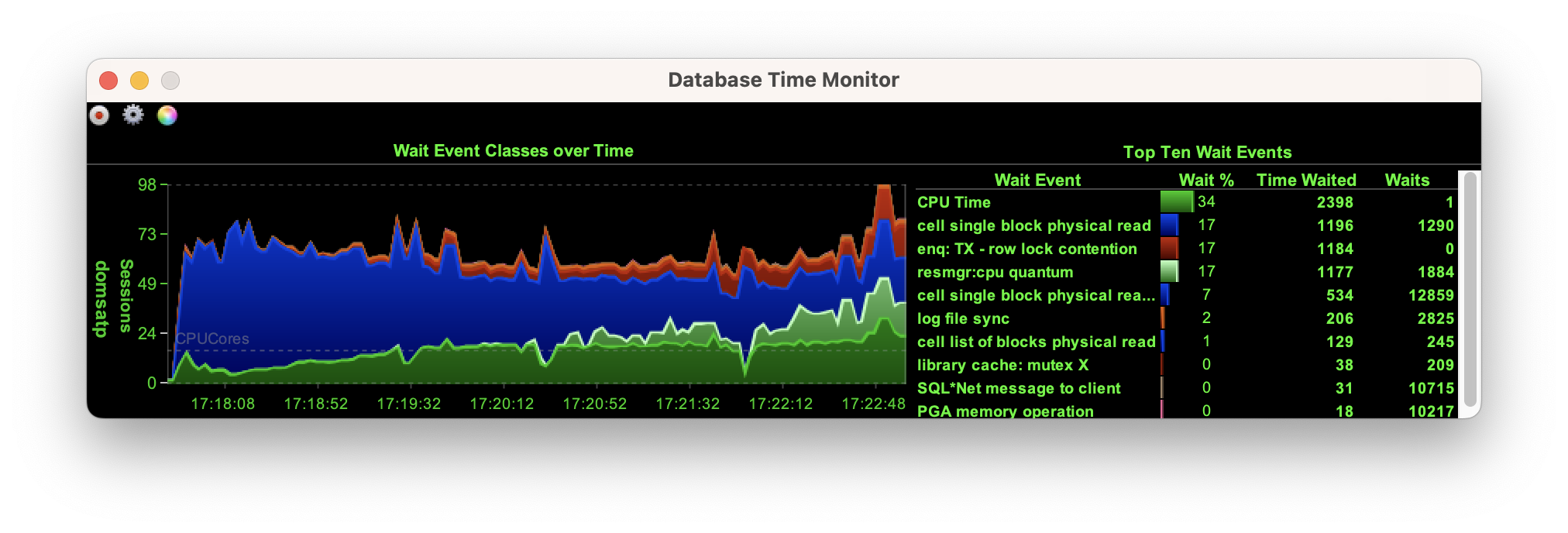
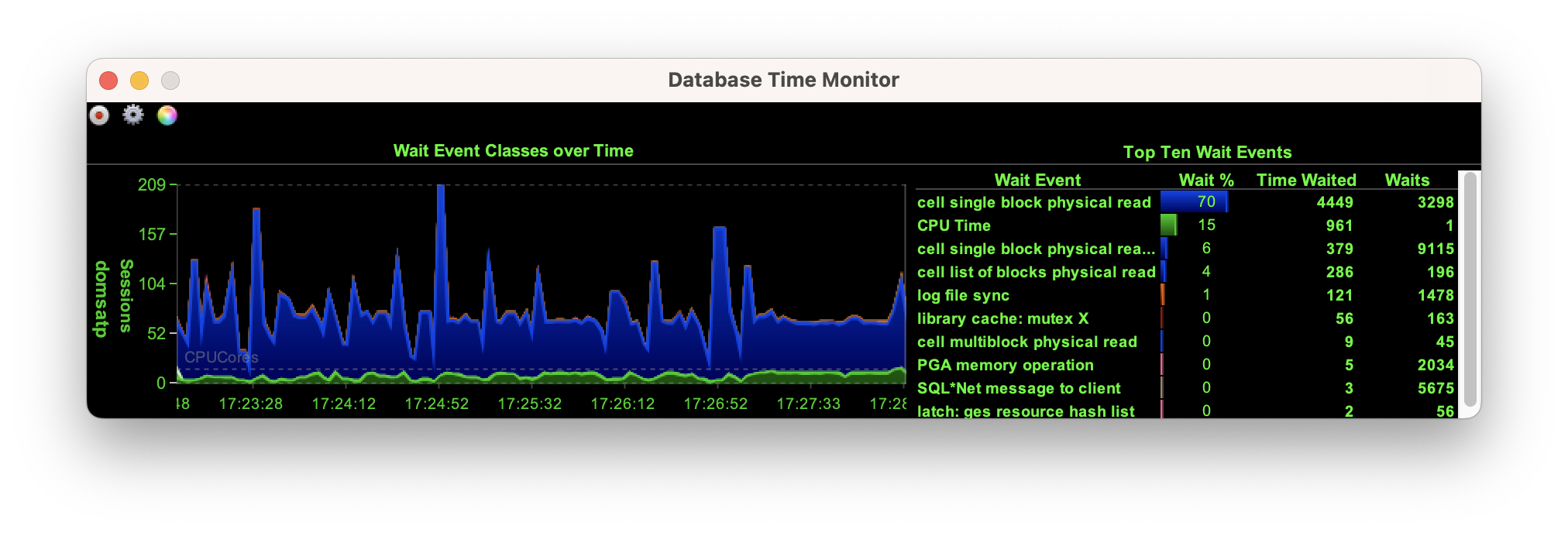
However, at a scale of a thousand the database is forced to retrieve every block from the storage cells, shown here with the wait on “cell single block physical read”.
When testing with Swingbench, especially if you are looking to compare cloud services, hardware, database features etc. Always look to create a dataset that represents the size of your target system to properly understand the capabilities of those services.
I’m pleased to announce the release of Swingbench 2.8. It includes A new html front end to run and review benchmark runs New tool to render results with...
I’ve added a new tool (added in September 2025) to enable you to compare benchmark results that are generated and stored in the database (see here). The tool...
There’s a new version of swingbench that includes the TPC-C benchmark and a tool to extract benchmark results from the database and export them as text or cs...
I’ve just added some functionality to Swingbench that I probably should have added a long time ago. Now, every time you run a benchmark using Charbench, Swin...
I know it’s been a while since we’ve had a swingbench update. Thats mainly because of work commitments and “life”. Thats not to say there hasn’t been work go...
A small but significant set of changes Last weekend I updated swingbench to add a few features that I’ve had frequent requests for. One is the addition of da...
A new build of Swingbench with a whole bunch of small changes mainly related to the benchmarks. Faster build time for the JSON benchmark when creating lar...
In my previous post “Going Big” I discussed the difference testing a data set of a representative size can make to the usefulness of a benchmark. Running a w...
Swingbench makes it simple to generate a dataset that you can simulate transactions against. However one of the problems I commonly see is that the users of ...
To celebrate the new release of “Oracle Database Free 23c : Developer Release” I’m releasing a new build of swingbench. This build includes a new “Movie Stre...
Swingbench 2.7 So I finally found some time to get a new build of swingbench done. The big change is that swingbench now only supports JDK-17 and above. Now,...
Hybrid Partitioned tables continues to be one of my favorite features of Oracle Database 19c and they’ve gotten better over time as we’ve introduced new feat...
Following quickly on the heels of the update to MonitorDB I’m releasing a new build of DBTimeMonitor. This is a simple update using the latest Oracle jdbc dr...
I’ve just updated MonitorDB. It’s never going to replace Grafana but if you need a quick solution to monitor a few values inside of the Oracle Database and y...
This short blog isn’t about best practices when conducting benchmarks. I think there are plenty of formal papers on the subject available with just a quick G...
I’ll make a confession. I don’t own a Microsoft Windows Machine. I never have and probably never will. This means that I generally never get the oppertunity ...
A New Release of Swingbench… Along with a new website, I’m rolling out a new build of Swingbench. This release is a little embarrassing for me, as it include...
A New Start… Quite a lot has changed since I last posted on this website. I had just left Oracle to join Google… A year and a half later I returned to Oracle...