results2text: Benchmark Comparisons
I’ve added a new tool (added in September 2025) to enable you to compare benchmark results that are generated and stored in the database (see here). The tool...

Swingbench makes it simple to generate a dataset that you can simulate transactions against. However one of the problems I commonly see is that the users of swingbench often complain that the default settings used by the wizards to build the dataset result in workloads that don’t push the I/O of their database’s hardware. This perhaps isn’t a surprise, I’m very conservative in the defaults I use. I have no idea what the underlying hardware a user has available to them.
Building a dataset that reflects the end user of a database is important. There’s very little value in building an Order Entry workload of scale 10 (10 GB of Data and 7 GB of Indexes) if you want to try and simulate how your application’s database might behave if it’s of size 10TB of data and 5TB of Indexes. To support such a database you’re likely using a server with a significant amount of memory and a powerful I/O sub-system. Building your database at a scale of 10 means that the tables in the Order Entry schema will be entirely cached in memory and would only use the I/O subsystem for writing any changes to the database. This means any comparison of any workload between Swingbench and your application’s workload is already compromised. A much more realistic comparison would be to scale order entry dataset to be comparable to your target application’s dataset and reflect the same I/O profile (more on this in a following blog).
However, another common complaint I often hear is that building a dataset of any significant size takes too long. In many instances that issue can be avoided if the following guidelines are followed.
sbutil. It’s a multi-purpose swingbench utility that will allow you to validate, fix and more importantly duplicate/grow a Swingbench schema. It duplicates/grows a Swingbench schema in the database using parallel and direct operationsnohup to run the build detached from the load-generator, meaning you don’t need to babysit it.I’m going to build a 1TB (1.7TB with indexes) Order Entry dataset. I’ll do this on ADB as it’s fast and a machine I have easy access to. The approach documented below will work against any version of the database. For the purposes of this test I have pre-created my database and have installed Swingbench on a 8 OCPU VM in the same VPN (virtual private network) as my database. Ideally, as indicated in the points above, I’d like to install Swingbench on the server running my database to remove network-latency. However for most cloud databases that isn’t likely to be an available approach. The first step is to build a seed dataset. This can be of any size typically I like to create one in the range 5-10 GB is size. I’ll use 10GB to keep the numbers simple. I’ll also be using the command like rather than a GUI to enable me to trivially script the process.
So the first command is
./oewizard -v -cs domsatp -u soe -p YourPassw0rd -scale 10 -tc 128 -cl -dba admin -dbap YourPassw0rd! -sp 64 -create -noindexes -ro -bs 2048
The command asks the wizard to build an Order Entry schema of scale 10 using 128 threads. It specifies the dba username (admin on ADB) and the dba password. You’ll need to change these to reflect your environment. It also indicates that there’s no need to build indexes as we’ll rebuild them later after we scale the benchmark to 1TB. I also use the -sp command to create more data chunks for the oewizard to use. I’ve also increased the batch size of the inserts to 2048 from the default of 200.
You’ll get a report similar to the following
Data Generation Runtime Metrics
+-------------------------+-------------+
| Description | Value |
+-------------------------+-------------+
| Connection Time | 0:00:00.004 |
| Data Generation Time | 0:04:28.229 |
| DDL Creation Time | 0:02:54.719 |
| Total Run Time | 0:07:22.954 |
| Rows Inserted per sec | 561,163 |
| Actual Rows Generated | 150,485,378 |
| Commits Completed | 7,871 |
| Batch Updates Completed | 73,854 |
+-------------------------+-------------+
This shows we were inserting roughly half a million rows a second inserting over 150 million rows
Ideally you should create a script i.e. buildschema.sh with all the commands in and run it with nohup i.e.
nohup ./buildschema.sh &
The command above will write all the output of oewizard to a file called nohup.out allowing you to monitor at a later time. Regardless of whether you run the command interactively or via nohup you should end up with a table like this.
The next tool we’ll use is SBUtil. SBUtil is a utility that allows us to validate, fix and scale datasets created by Swingbench. It’s run from the command line and has no graphical front end. To validate the order entry data set we’ve just generated. use a command similar to the following replacing the connect string and passwords to reflect your environment.
./sbutil -soe -cs domsatp -u soe -p YourPassw0rd -val
There appears to be an issue with the current Order Entry Schema. Please see below.
--------------------------------------------------
|Object Type | Valid| Invalid| Missing|
--------------------------------------------------
|Table | 10| 0| 0|
|Index | 0| 0| 26|
|Sequence | 5| 0| 0|
|View | 2| 0| 0|
|Code | 1| 0| 0|
--------------------------------------------------
List of missing or invalid objects.
Missing Index : PRD_DESC_PK, PROD_NAME_IX, PRODUCT_INFORMATION_PK, PROD_SUPPLIER_IX, PROD_CATEGORY_IX, INVENTORY_PK, INV_PRODUCT_IX, INV_WAREHOUSE_IX, ORDER_PK, ORD_SALES_REP_IX, ORD_CUSTOMER_IX, ORD_ORDER_DATE_IX, ORD_WAREHOUSE_IX, ORDER_ITEMS_PK, ITEM_ORDER_IX, ITEM_PRODUCT_IX, WAREHOUSES_PK, WHS_LOCATION_IX, CUSTOMERS_PK, CUST_EMAIL_IX, CUST_ACCOUNT_MANAGER_IX, CUST_FUNC_LOWER_NAME_IX, ADDRESS_PK, ADDRESS_CUST_IX, CARD_DETAILS_PK, CARDDETAILS_CUST_IX,
You’ll notice that the sbutil command shows that we are missing indexes. This is to be expected as we asked the oewizard not to create them. Our next step is to duplicate the dataset to 1TB. This means we need to scale the dataset 100 times. This is done with the -dup <n> command. It’s also worth noting that it’s possible sort and compress the data at the same time. However in this instance, all we want to do is to duplicate it and rebuild the indexes. To do this all we need is to run this command.
./sbutil -soe -cs domsatp -u soe -p YourPassw0rd -dup 100 -parallel 64
You should get output similar to the following
Getting table Info
Got table information. Completed in : 0:00:04.440
Dropping Indexes
Dropped Indexes. Completed in : 0:00:00.324
Creating copies of tables
Created copies of tables. Completed in : 0:00:00.136
Begining data duplication
Completed Iteration 100. Completed in : 0:01:29.712
Creating Constraints
Created Constraints. Completed in : 1:11:57.904
Creating Indexes
Created Indexes. Completed in : 2:55:38.984
Updating Metadata and Recompiling Code
Updated Metadata. Completed in : 0:00:25.785
Updating Sequences
Updated Sequences. Completed in : 0:00:59.413
Determining New Row Counts
Got New Row Counts. Completed in : 0:01:40.052
+--------------+--------------------+---------------+---------------+----------+
| Table Name | Original Row Count | Original Size | New Row Count | New Size |
+--------------+--------------------+---------------+---------------+----------+
| ORDER_ITEMS | 71,671,900 | 5.1 GB | 7,167,190,000 | 513.9 GB |
| CUSTOMERS | 10,000,000 | 1.5 GB | 1,000,000,000 | 149.6 GB |
| CARD_DETAILS | 15,000,000 | 936 MB | 1,500,000,000 | 95.1 GB |
| ORDERS | 14,297,900 | 2 GB | 1,429,790,000 | 198.1 GB |
| INVENTORIES | 898,523 | 19 MB | 898,523 | 19.1 MB |
| ADDRESSES | 15,000,000 | 1.3 GB | 1,500,000,000 | 133.5 GB |
| Total | | 10.8 GB | | 1.1 TB |
+--------------+--------------------+---------------+---------------+----------+
This shows that each duplication of the data is taking about 1 minute 30 seconds. Roughly 4 times faster than generating the data using the wizard.
Whilst this approach of building large data sets will be much quicker than using a wizard it will still take some time to complete. As before I recommend using nohup to ensure that it completes using a command similar to the following
nohup ./sbutil -soe -cs domsatp -u soe -p YourPassw0rd -dup 100 -parallel 64 &
The first thing you should do after running this step is to check that all of the indexes and other structures have been built correctly. you can do this with the following command
./sbutil -soe -cs domsatp -u soe -p YourPassw0rd -val
It should show you something similar to this
The Order Entry Schema appears to be valid.
--------------------------------------------------
|Object Type | Valid| Invalid| Missing|
--------------------------------------------------
|Table | 10| 0| 0|
|Index | 26| 0| 0|
|Sequence | 5| 0| 0|
|View | 2| 0| 0|
|Code | 1| 0| 0|
--------------------------------------------------
If it shows that some indexes are missing try and rebuild them with
./sbutil -soe -cs domsatp -u soe -p YourPassw0rd -ci -parallel 48
If it shows that the stored procedure didn’t compile try and rebuild it with
./sbutil -soe -cs domsatp -u soe -p YourPassw0rd -code
You should end up with output showing all objects appear valid for your schema.
| Operation | Time Taken |
|---|---|
| Build 10GB order entry data set without indexes | 7 min 22 s |
| Scale data order entry data set | 2 hours 46 min 40 s |
| Create constraints | 1 hour 11 min 57 s |
| Create indexes | 2 hours 55 min 38 s |
| Total Time | 7 hours 1 min 37 s |
So nearly exactly 7 hours in total. Clearly, the process would be faster if a more powerful shape was used. It’s also a great measure of the power of a platform (server and database) if all of the key objects are kept consistent i.e. JVM version, Database version etc.
The initial build of the data set. The initial data generation step using oewizard was relatively quick (7 mins) and placed little load on the database server as shown below.
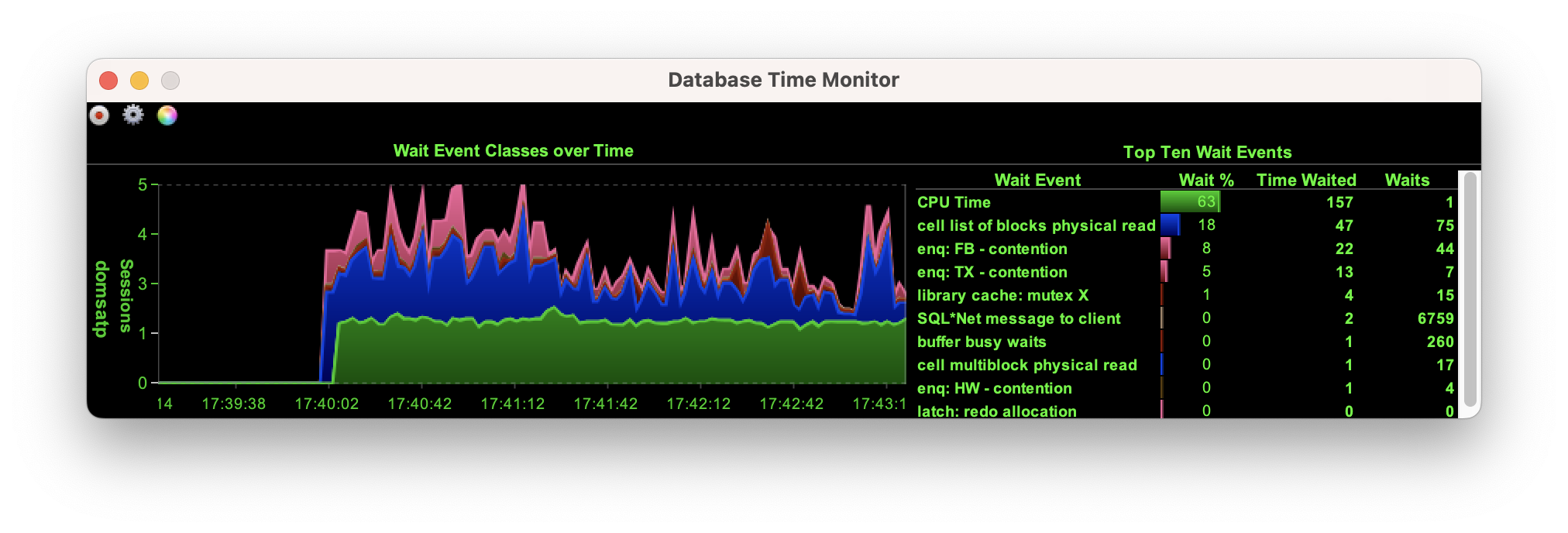 Most of the effort was on the 8 OCPU VM running
Most of the effort was on the 8 OCPU VM running oewizard which for parts ran at 100% utilization where as the database never really ran at more than 40% utilization. Most of the wait events were on processes on the CPU and sessions waiting on I/O. This is to be expected and looked very healthy.
The data scale up was much more demanding on the database and had almost no impact on the VM running sbutil. Again no real surprises then.
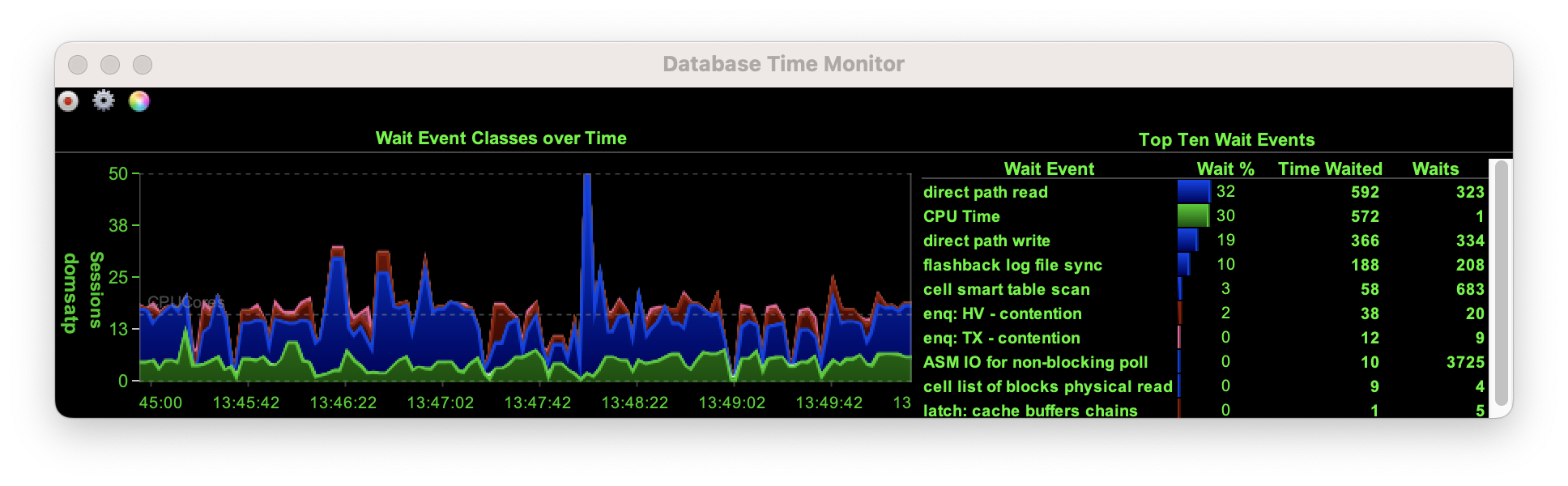 There were a few wait events that I’ll investigate. I saw a number of waits on
There were a few wait events that I’ll investigate. I saw a number of waits on enq:HV and enq:HW. Whilst these weren’t un-expected as I’m pushing a lot of data into the database with insert /*+ APPEND */. I think there’s probably some optimisations I could do about sizing extents correctly.
This post is already getting too long. The next post will show performance differences and wait events between a 1, 10, 100 and 1000 scale Order Entry benchmark.
I’ve added a new tool (added in September 2025) to enable you to compare benchmark results that are generated and stored in the database (see here). The tool...
There’s a new version of swingbench that includes the TPC-C benchmark and a tool to extract benchmark results from the database and export them as text or cs...
I’ve just added some functionality to Swingbench that I probably should have added a long time ago. Now, every time you run a benchmark using Charbench, Swin...
I know it’s been a while since we’ve had a swingbench update. Thats mainly because of work commitments and “life”. Thats not to say there hasn’t been work go...
A small but significant set of changes Last weekend I updated swingbench to add a few features that I’ve had frequent requests for. One is the addition of da...
A new build of Swingbench with a whole bunch of small changes mainly related to the benchmarks. Faster build time for the JSON benchmark when creating lar...
In my previous post “Going Big” I discussed the difference testing a data set of a representative size can make to the usefulness of a benchmark. Running a w...
Swingbench makes it simple to generate a dataset that you can simulate transactions against. However one of the problems I commonly see is that the users of ...
To celebrate the new release of “Oracle Database Free 23c : Developer Release” I’m releasing a new build of swingbench. This build includes a new “Movie Stre...
Swingbench 2.7 So I finally found some time to get a new build of swingbench done. The big change is that swingbench now only supports JDK-17 and above. Now,...
Hybrid Partitioned tables continues to be one of my favorite features of Oracle Database 19c and they’ve gotten better over time as we’ve introduced new feat...
Following quickly on the heels of the update to MonitorDB I’m releasing a new build of DBTimeMonitor. This is a simple update using the latest Oracle jdbc dr...
I’ve just updated MonitorDB. It’s never going to replace Grafana but if you need a quick solution to monitor a few values inside of the Oracle Database and y...
This short blog isn’t about best practices when conducting benchmarks. I think there are plenty of formal papers on the subject available with just a quick G...
I’ll make a confession. I don’t own a Microsoft Windows Machine. I never have and probably never will. This means that I generally never get the oppertunity ...
A New Release of Swingbench… Along with a new website, I’m rolling out a new build of Swingbench. This release is a little embarrassing for me, as it include...
A New Start… Quite a lot has changed since I last posted on this website. I had just left Oracle to join Google… A year and a half later I returned to Oracle...