Swingbench 2.8
I’m pleased to announce the release of Swingbench 2.8. It includes A new html front end to run and review benchmark runs New tool to render results with...
This short blog isn’t about best practices when conducting benchmarks. I think there are plenty of formal papers on the subject available with just a quick Google search. This blog is about a specific question I get asked regarding running tests using swingbench. Which is
“Should I restore the database after each swingbench benchmark run to ensure I’m running against the same dataset?”
Generally I say “Yes”. But like a lot of answers I give, it’s quickly followed with “But it depends”. It makes perfect sense to want to rerun a workload against the database to measure a metric like throughput or latency. Each successive run should give you the same result, or at least you’d think so. This is referred to as “Repeatability” or more formally “Test Retest Reliability”. However it’s worth remembering that it’s not always possible to achieve repeatable results for a benchmark like TPC-C or swingbench’s “Order Entry” or indeed any other database workload. Databases, because of their inherent complexity, work against you in this respect. It can be extremely challenging to get databases to produce benchmark results that are consistently within 5% for key metrics on each run.
When I started working on databases and got involved in benchmarking, we usually did benchmarks in a very controlled environment. It was typically conducted at the hardware manufactures test facilities. We had hardware and operating systems specialists around to help us conduct the tests. We had dedicated hardware to run workloads that would be laughable by todays standards. We would religiously restore the database after each run to ensure consistency. And even then it was still near impossible to get results that were within 5% of one another. So depending on the customers methodology we’d average out 3 runs or they’d take our best result.
I guess what I’m saying is that for databases running tens of thousands of transactions per second, getting a consistent result is hard. When your conducting tests on cloud infrastructure the likely hood of getting results with 5% of one another is harder still especially if you are working in a VM thats shared with other cloud users.
So coming back to the original question “Should I restore the database after each swingbench benchmark run?”. For a test where your making significant investments based on the findings of a test, then it probably makes sense to follow a formal process and ensure that you have the conditions as close as possible to one another for each run. This will involve a full restore or a repopulation of the database with the same data. This takes time and is typically a resource intensive operation. If however you are looking at less formal testing, perhaps evaluating a feature or the difference additional memory might make for a given workload then I’d recommend just re-running against the same initial dataset for each successive run. The reason for this is that swingbench maintains a table of CUSTOMERS and ORDERS rows counts. It uses this table to define the limits of random numbers used by the various transactions. This means that whilst each run adds more data and modifies data structure like indexes, it doesn’t have a dramatic impact. So whilst the dataset grows the impact of that growth isn’t dramatic.
The following chart attempts to show what this looks like. It shows the results of 18 runs of the simple order entry benchmark, each an hour long. Each benchmark was run straight after one another. The schema started at a scale of 100 (which is roughly 100GB in data size and 80GB of indexes). After 18 hours at roughly 2,500 TPS (Or roughly 45,000 SQL operations a second) the dataset had grown to roughly 145GB in size with the largest table being just shy of a billion rows.
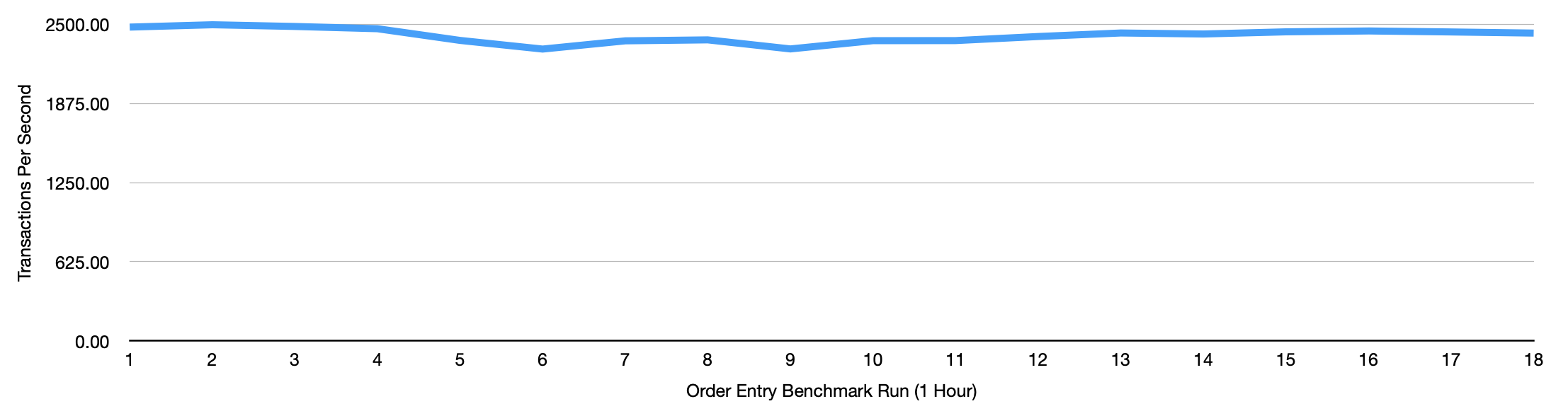
The standard deviation for all 18 runs was just 56. So on this particular instance all of the runs were pretty close in terms of average throughput.
If however you want to update the meta data for order entry between each run you can do this with the following command.
./sbutil -soe -cs <connection string> -u <username> -p <password> -uc
Each time this command is run the meta data is updated to reflect the new row counts in the CUSTOMERS and ORDERS tables. This can have an impact on the overall performance between runs and definitely lead to more variation between runs.
So in summary. For tests that are limited in length that don’t change the benchmarks metadata there’s little benefit of doing a full restore between runs.
If you’d like to reproduce this test. you can use the following commands in swingbench you use the following commands as a guide
The following will create a 100 scale order entry schema
./oewizard -c oewizard.xml -v -cs <connection string> -p <password> -scale 5 -tc 24 -create -cl -dba <dba username> -dbap <dba password>
./sbutil -soe -cs <connection string> -u <username> -p <password> -dup 20 -parallel 16
And the following will run the orderentry benchmark 9 times with each run lasting 1 hour. It will also print out the size of the tables and indexes at the start and end of each run.
#!/bin/bash
cd ~/swingbench/bin
./sbutil -soe -cs domsatphigh -u soe -p ReallyLongPassw0rd -tables
./sbutil -soe -cs domsatphigh -u soe -p ReallyLongPassw0rd -indexes
./charbench -s -nc -cs domsatp -u soe -p ReallyLongPassw0rd -uc 24 -rt 1:00 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0
./charbench -s -nc -cs domsatp -u soe -p ReallyLongPassw0rd -uc 24 -rt 1:00 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0
./charbench -s -nc -cs domsatp -u soe -p ReallyLongPassw0rd -uc 24 -rt 1:00 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0
./charbench -s -nc -cs domsatp -u soe -p ReallyLongPassw0rd -uc 24 -rt 1:00 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0
./charbench -s -nc -cs domsatp -u soe -p ReallyLongPassw0rd -uc 24 -rt 1:00 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0
./charbench -s -nc -cs domsatp -u soe -p ReallyLongPassw0rd -uc 24 -rt 1:00 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0
./charbench -s -nc -cs domsatp -u soe -p ReallyLongPassw0rd -uc 24 -rt 1:00 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0
./charbench -s -nc -cs domsatp -u soe -p ReallyLongPassw0rd -uc 24 -rt 1:00 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0
./charbench -s -nc -cs domsatp -u soe -p ReallyLongPassw0rd -uc 24 -rt 1:00 -c ../configs/SOE_Server_Side_V2.xml -mr -intermin 0 -intermax 0
#./sbutil -soe -cs domsatphigh -u soe -p ReallyLongPassw0rd -tables
#./sbutil -soe -cs domsatphigh -u soe -p ReallyLongPassw0rd -indexes
I’m pleased to announce the release of Swingbench 2.8. It includes A new html front end to run and review benchmark runs New tool to render results with...
I’ve added a new tool (added in September 2025) to enable you to compare benchmark results that are generated and stored in the database (see here). The tool...
There’s a new version of swingbench that includes the TPC-C benchmark and a tool to extract benchmark results from the database and export them as text or cs...
I’ve just added some functionality to Swingbench that I probably should have added a long time ago. Now, every time you run a benchmark using Charbench, Swin...
I know it’s been a while since we’ve had a swingbench update. Thats mainly because of work commitments and “life”. Thats not to say there hasn’t been work go...
A small but significant set of changes Last weekend I updated swingbench to add a few features that I’ve had frequent requests for. One is the addition of da...
A new build of Swingbench with a whole bunch of small changes mainly related to the benchmarks. Faster build time for the JSON benchmark when creating lar...
In my previous post “Going Big” I discussed the difference testing a data set of a representative size can make to the usefulness of a benchmark. Running a w...
Swingbench makes it simple to generate a dataset that you can simulate transactions against. However one of the problems I commonly see is that the users of ...
To celebrate the new release of “Oracle Database Free 23c : Developer Release” I’m releasing a new build of swingbench. This build includes a new “Movie Stre...
Swingbench 2.7 So I finally found some time to get a new build of swingbench done. The big change is that swingbench now only supports JDK-17 and above. Now,...
Hybrid Partitioned tables continues to be one of my favorite features of Oracle Database 19c and they’ve gotten better over time as we’ve introduced new feat...
Following quickly on the heels of the update to MonitorDB I’m releasing a new build of DBTimeMonitor. This is a simple update using the latest Oracle jdbc dr...
I’ve just updated MonitorDB. It’s never going to replace Grafana but if you need a quick solution to monitor a few values inside of the Oracle Database and y...
This short blog isn’t about best practices when conducting benchmarks. I think there are plenty of formal papers on the subject available with just a quick G...
I’ll make a confession. I don’t own a Microsoft Windows Machine. I never have and probably never will. This means that I generally never get the oppertunity ...
A New Release of Swingbench… Along with a new website, I’m rolling out a new build of Swingbench. This release is a little embarrassing for me, as it include...
A New Start… Quite a lot has changed since I last posted on this website. I had just left Oracle to join Google… A year and a half later I returned to Oracle...